Continuing the discussion from Radicle Collaboration Tools:
Jammin’
The @coco team decided to have a jamboard session over hangouts. We wanted to flesh out the matters around representation and consistency of users’ issue trackers. No easy feat as you may be able to tell from the previous back and forth in the above conversation.
In this thread I want to cover what we discussed and the outcomes so that we can further drive the conversation forward and help inform the final implementation. We want to focus the conversation on these new outcomes.
Our conversation started off with an overview of what ideas we have explored, whether it was on discourse or over hangout sessions. The overview is shown in the image below:
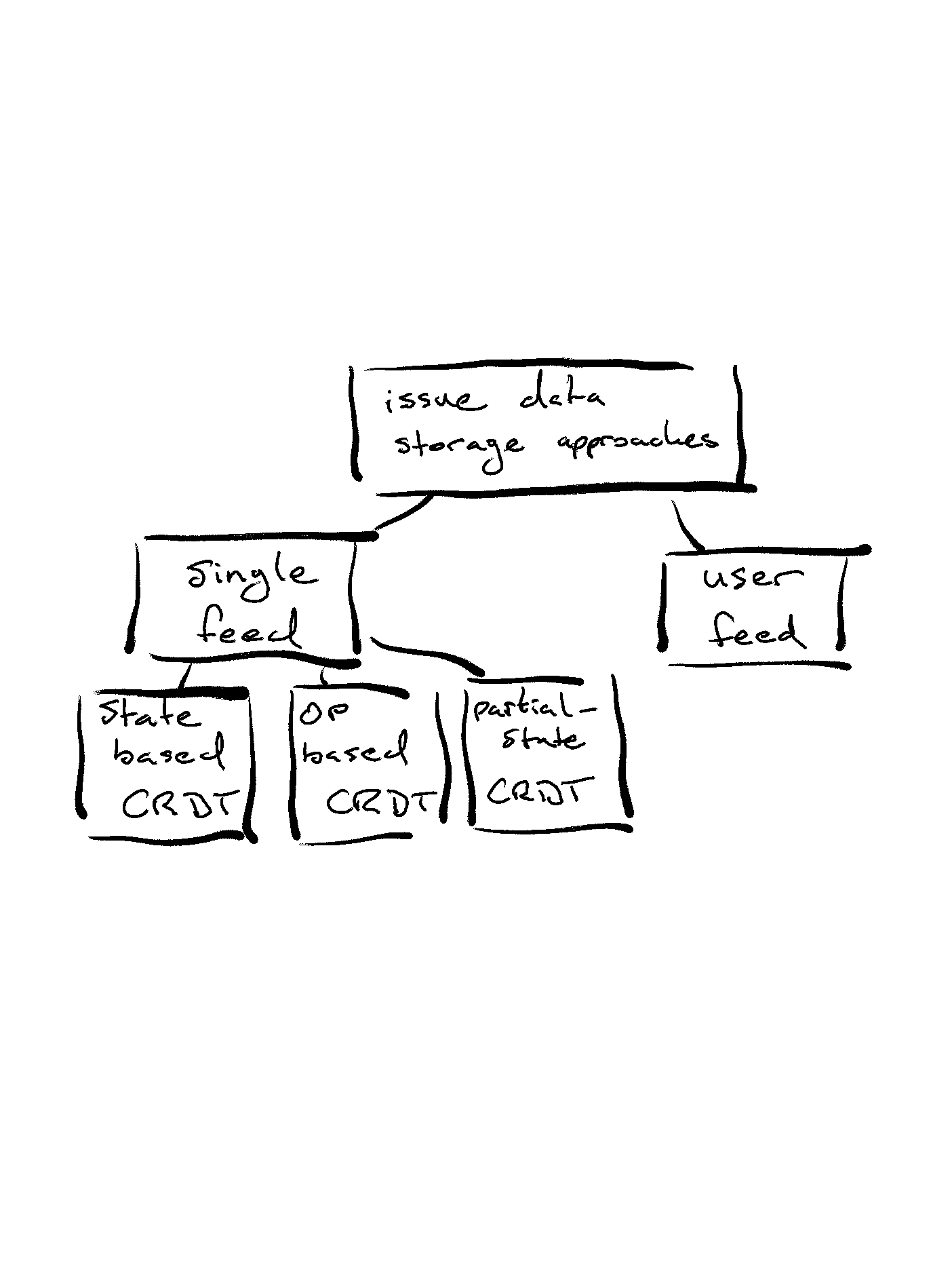
We split the conversations into “Single Feed” and “User Feed”. “Single Feed” is where we were exploring the options of CRDTs to create and maintain an issue feed.
On the flip-side we have “User Feed”, which is more reminiscent of SSB’s social feed. Each user holds their own version of the feed, merging in another feed as they discover them. The user’s define their own terms of what they see and merges happen based on a timeline using references and timestamps.
In a user based feed the model in the .git database would map to a branch per person. So for example, in my .git folder I could see the following if I was following massi and kim:
# My issue tracker
refs/remotes/heads/.rad/issues/issue-1234
# My copy of massi's tracker
refs/remotes/massi/.rad/issues/issue-1234
# My copy of kim's tracker
refs/remotes/kim/.rad/issues/issue-1234
You get a Merkle! And You get a Merkle!
We noticed that there was a relation between this user based model and the Merkle-CRDT model posted previously:
So we decided to explore what it would look like for a user based feed as DAGs.
User’s each have their own DAG of commits that represent their view, and by merging them based on the rules outlined in the paper we should, theoretically, always arrive at a consistent view of the issue. This view would be a “Staging View” that is built from the individual feeds. Let’s break this idea down a little further with some more drawings!
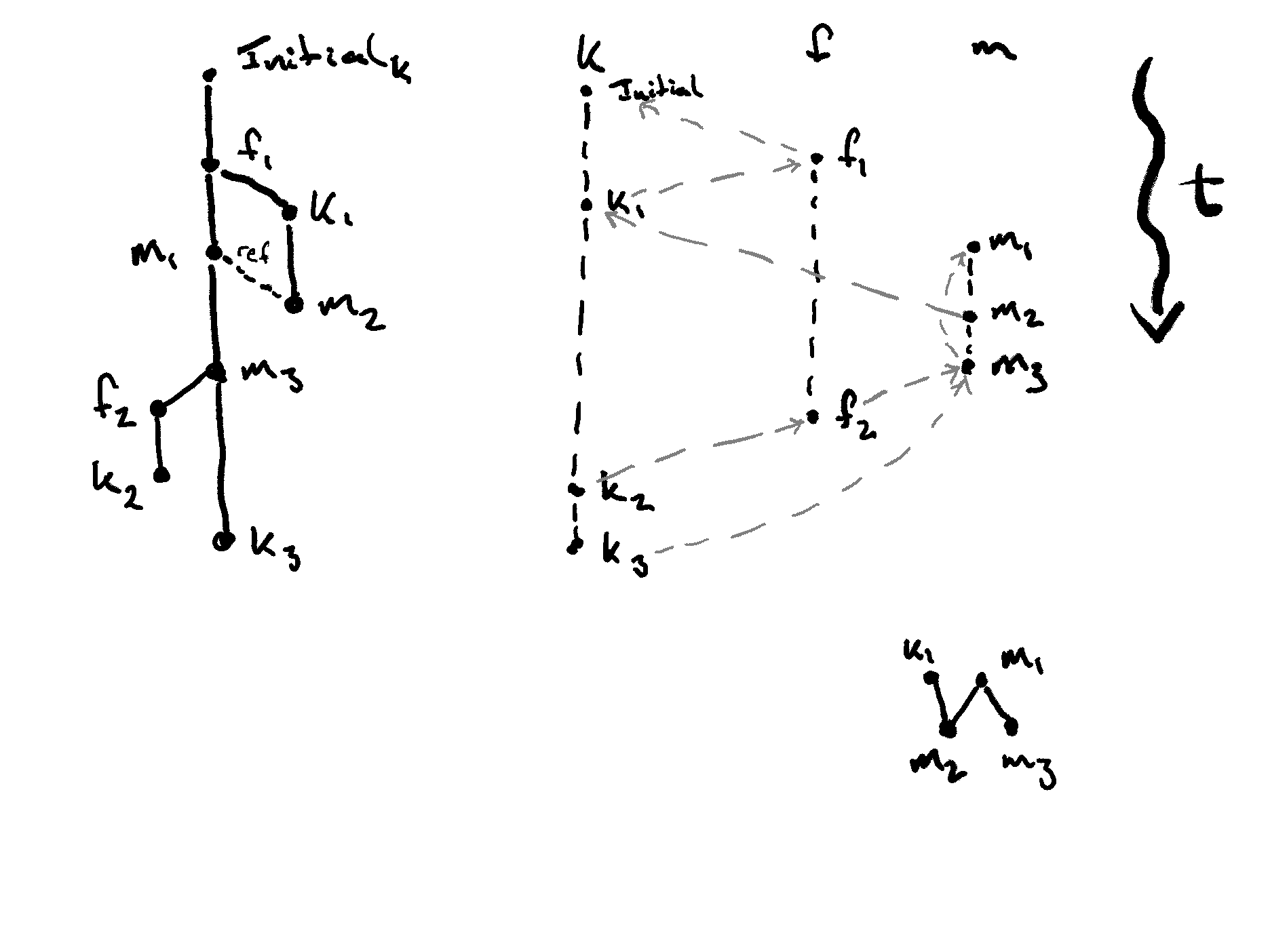
On the far left of the diagram we visualise what an issue thread might look like. To personalise the story we have k, m, and f for Kim, Massi, and Fintan. The node in the graph m1 denotes Massi’s first comment. The Initial_k comment is the start of the issue and the main thread.
The main thread is made up of Initial_k, f1, m1, m3, and k3. The first thread is branched off of f1 and is followed by k1 and m2. Finally, we also note that m2 references m1.
In the bottom right we show the cluster of k1, m1, m2, and m3. The point here is that both m1 and k1 are both parents of m2. k1 is a parent because it happened before m2 in the thread. m1 is a parent of m2 because m2 references m1 and this implies that m1 must exist beforehand. m1 is the parent of m3 because they appear in sequence on the main thread.
In the next pane over from the issue graph we have a timeline of the comments made by each person where the grey, dashed lines denote the relationships across the user’s timelines. This shows that a user’s timeline could be their own DAG of commits, the user based feeds, referencing other user’s commits when they are aware of them.
Thus, the timelines on the right of the diagram would be merged into the “Staging Branch”, which is our graph on the left of the diagram. The merging rules should be simple. Comments will be ordered by their insertion into a thread. If there are references from other comments they will be linked together and create a causal order. If comments happen concurrently under a thread comment then these will be merged either by causal order or fall back to total order e.g. based on timestamp. We don’t mind the order in this case since the chances are that the comments will be in context of the existing conversation anyway.
At this point we marry the DAGs with an Operation-based CRDT, as recommended by the previously mentioned Merkle-CRDT paper. And when we look at the leaves of the graph we would produce a snapshot of the total state, and this would form the view for the application.
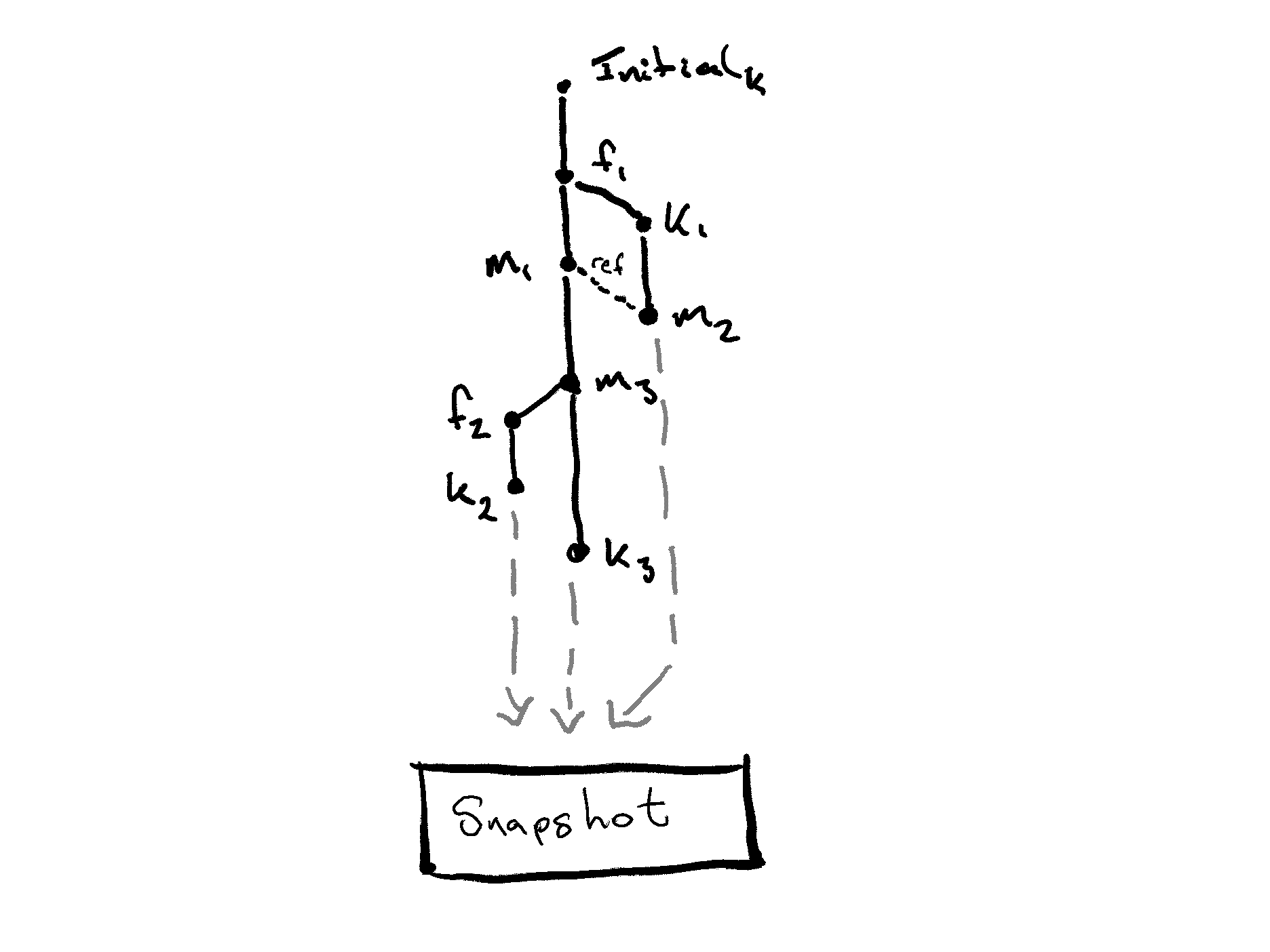
Outcome
To wrap up the outcomes of the discussion were the following take homes:
- We will have one feed per user
- A feed will consist of operations that will form an op-based CRDT
- We merge feeds into a staging based on two rules in order:
- Causality
- Fallback to total order e.g. timestamp, lexicographical order of hash
- We create a snapshot of the merged view
- Operation semantics will be needed here
- Two merged views can be easily compared by their root hashes to see if they are equal and if not a user can identify which comments they are missing.
The protocol will only manage the DAGs and merging, whereas a layer above that will define the op-based semantics.
Follow Up
The next stage of research will be around the operation semantics. We will look at git-bug and their great work in this area for inspiration while also being informed by our current research in CoCoDa: Issues 🗒 #codecollab.
In git-bug we’ll specifically be looking at what they are doing for their caching layer, which will help us think about our snapshots and also the query types they found useful.